web6047 - 2025年 7月
ここは個人の趣味のページです。
私がプログラミングを好むわけは、プログラミングは私の「物づくり」に対する探求心と創造性を十分に満たしてくれるからです。
- 探求心:
ファミコン版「ドラゴンクエスト」に衝撃を受け、憧れて、そのための断片的なプログラムを作ることを楽しんできました。
断片的なプログラムとは、「マップを描画するだけ」とか、「プレイヤーキャラを動かすだけ」とかです。
そういう憧れに向かうステップ(探求)に、心躍る喜びがありました。 - 創造性:
この創造性とはアイデアを形にする喜びのことです。
もともと自分のアイデアを形にする「ペーパークラフト」や「木工」などのモノ作りが好きだったので、プログラミングとの相性が良かったようです。
ここの管理人、
AI の利用やめるってよ。
AI の問題点:
- 自分で考えずに AI を利用することで、考える力が減退する。
- 人と人との交流(教わる)が減る。
- 創作物のオリジナリティが無くなる。(自分の力で作ることの喜びが減る)
- 犯罪に使われている。
これらが向こう10年解決されないだろうと見込んで、やめることにしました。(2025年5月23日~)
私は AI に頼らず「自分の力」を大切にしたいです。
…とはいえ、人間は新しく見つけた技術を手放すということは基本的にやらないと思います。
だから私も後々 AI を利用することにはなると思います。
でも上記の問題点は確かなもので、将来 AI ロボが私の家の扉をコンコンと叩いて
「市からの要請で、お手伝いするため おうかがいしました」
と言うまでの間は、この AI 技術を導入せず、頑張ってみようと思います。
でもこの考え方、キツイと思うのでマネしなくていいです。
- Special Documents -
特別な記事へのリンク

サンプル動作環境の作成方法



ゲームコーナー
(↑, ↓, ←, →)

(←, →, ↓, z, x)

その他 単発のアプリ




- 以降は日記です -

2025年7月10日
生活 最近の…
…買い物
Amazon で、「はじめの一歩」の第 1 話 ~ 第 38 話までを収録した DVD-BOX(中古)と、Mr.Children のアルバム(新品)を購入しました。
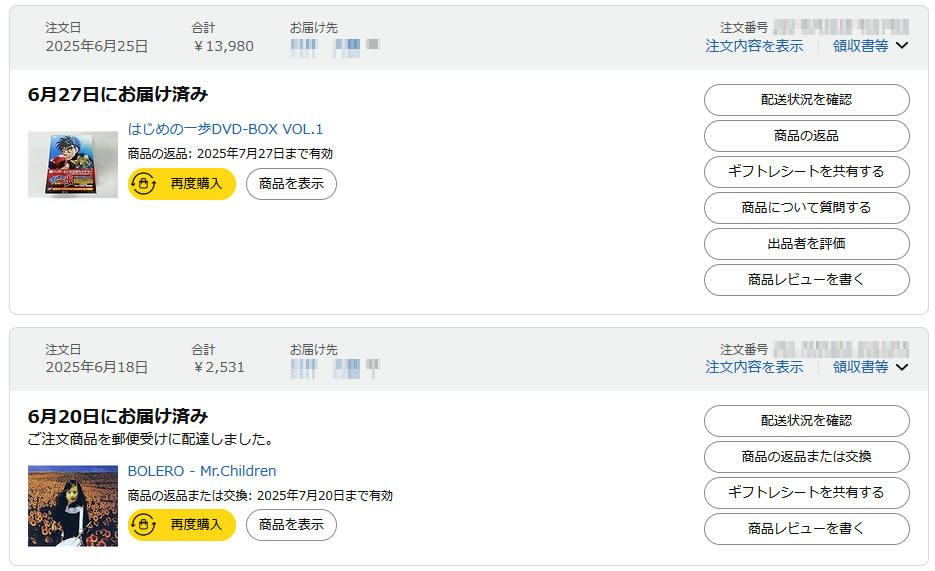
『はじめの一歩』は、
- いじめられっ子の幕の内一歩が、ボクシング新人王の鷹村と出会い、「強いってどんな気持ちですか?」、「僕もプロボクサーになりたい!」という想いを胸に、時には相手の強さを恐れリング上で逃げ出したい気持ちに襲われたり、打ちのめされてダウンして「まだだ!まだすべてを出し切っていない!」と言って立ち上がる様子、そういう強さへの挑戦みたいなところに引き付けられました。
- 闘いの中での駆け引きが RPG 開発の戦闘画面の参考になると思いました。
そんな理由で購入。
『Mr.Children』は、私が 15 才の頃だったかな。兄から「お前はミスチル聴いたほうが良い」と勧められたのに、180 度異なる中島みゆきを聴き始めた思い出があり、今思えば兄の言うことを聞いてミスチルでも良かったんじゃないか、、とちょっと思ったので買ってみました。
ヤフオクで、「Borland Turbo C++ 4.0J for DOS (PC-9801 & DOS/V用)」を落札しました。

「アップグレード」となっていますが、私はすでに「Borland Turbo C++ 1.01」を持っているので、そこからアップグレードできるでしょう。
でも当時は「アップグレード」と書いてあっても、旧バージョンが無くてもインストールできる場合が多かったのでその辺は心配ないかもしれません。(2025年7月26日追記:やはりそうで、普通にインストールできました)
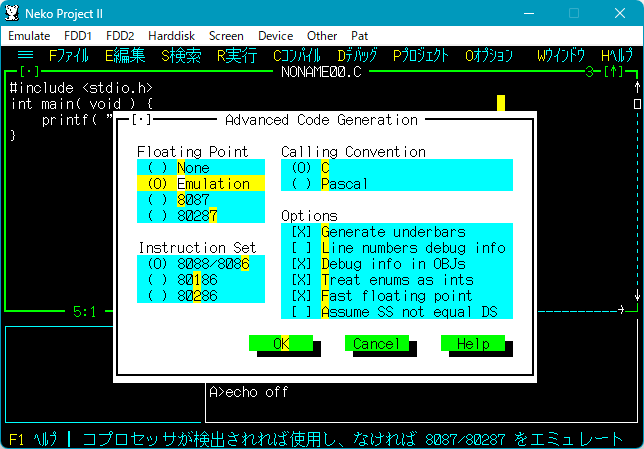
1.01 は Intel 8086 CPU と Intel 286 CPU 向けのコンパイルしかできませんが、 4.0 は Intel 386 CPU 向けのコンパイルが出来ます。
| ▼1.01 は Intel 8086 CPU と Intel 286 CPU まで。 | ▼4.0 では Intel 386 CPU が加わっている。 |
 |
 |
また、1.01 は「Turbo Debugger」がありませんが、4.0 には付属しています。「Turbo Debugger」が今回の主な目的です。
Turbo C++ は当時、海外でも販売されていましたが、海外では 3.0 までで、4.0 を発売したのは日本だけです。
しかし、4.0 には深刻なバグがあるという話をちょっと聞きました。
https://oshiete.goo.ne.jp/qa/455191.html(2025年9月17日(水)以降リンク切れする予定)
Tourbo-Cには4.0という恐ろしいバージョンがあって、強烈なバグを抱えたまま出荷されました。
DOS上のプログラムがTurbo-C4.0で開発されたものならバグ回避のためのコードが含まれている可能性が高く、移植時の問題になるかもしれません。
強烈なバグ:
プログラムが64キロバイトを超える配列を使っている場合、64キロバイトの境界線を越える要素のアドレス計算が間違っている。
それでもヤフオクで選んだのは、
- 書かれている通り64キロバイトを超えるときはバグ回避すれば良い。
- 同梱されている「Turbo Debugger」は良いソフトウェアだと評価されている。
https://en-m-wikipedia-org.translate.goog/wiki/Borland_Turbo_Debugger(Google Web翻訳)
BYTE誌は1989年1月、Turbo DebuggerをBYTE Awardsの「Distinction」受賞製品の一つとして選出しました。
同誌は、その使いやすさとTurbo PascalおよびTurbo Cとの統合性を高く評価し、「プログラマーの万能ツール」と評しました。 [ 5 ]
また、1989年2月号のCコンパイラ最適化に関する概説記事では、「最高のソースデバッガ」と評しました。 [ 6 ]
…私の身体
先月 6/1 に「そけい部ヘルニア(脱腸)」で1 週間入院しましたが、今は直っていつも通りの生活に戻っています。
でもときどき痛むので「何かあるな」と思っています。
それとは別件で、視力がこの1カ月、2カ月でグッと落ちました。
おなかの調子も正露丸を年に2~3ビンくらい「空ける」みたいな。
でも、もともとの性格でそういう調子が悪いところはどうとも思っていなくて、悲観の文字が無いかも。
…私の仕事

有名メーカーの工場に派遣され、産業用の電子機器を製造しています。
立ち仕事で座ることは許されず、それで毎日残業1時間があらかじめ決められているので、だいぶきつい。
でもやりがいがあるので、闘志を燃やして挑んでいるかんじ。
その闘志が私の身体を壊すんですけど、そういう性格だからしかたない。
…私の個人事業主の活動
今やっているクォータニオンのプログラムは、事業の一環としてやっています。
(下図は画像です)
画像の右上にはファイル名が表示されていて「web6047document-22.html」となっています。
前にも説明しましたが、「人体 3DCG モデル」のプログラムのために、もう 22 回目の作り直しをやっているという意味になっています。
作り直しを決めるたびに心が一瞬折れそうになるんですが、そう簡単にはくじけません。
そろそろ完成が見えてきたところです。
「人体 3DCG モデル」のために事業として設定している他のいろいろな活動を「止めている」ので早く完成してほしいんだけど、今年の秋くらいまでかかるだろうな。
この状況、事業としてやっているって言ったって、はたから見れば、私の今までの「プログラミングに明け暮れた生活」とあまり違いが無いんだよな…
いっぽう、イラスト投稿サイトの「イラストAC」でのイラストの売れ行きは、
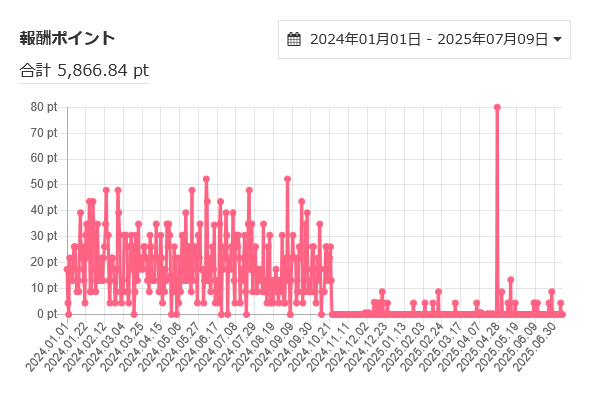
こんな感じ。2024年10月までは好調だったんですが、その月を境にパッタリ。
何が起こったのかというと、私の主力イラストの「ノートパソコン」に「マイクロソフトのウィンドウズマークが入っている」というのが問題になって、そのマークを訂正したんです。(自分でもちょっと気づかなかったですm(_ _)m)
訂正すると「投稿し直し」となってしまい、それが原因で、検索結果の上位だったものが下位に落ちてしまい、人々の目に入らなくなってしまった。。。ということかなと思っています。
残念と言えば残念だけど、まいっかと思っています。
事業としてやっているので、1つの商品についていちいち一喜一憂するという感覚はありません。
もともと性格がクールなので、、というのもあるかな。
あと生成 AI による画像提供があるから、「イラストAC」ってこの先もやっていけるのかなとちょっと疑問です。
でも生成 AI のイラストって、どこか血が通っていない感じがするというか、安っぽいというか、人の心に届かないというか…、あまり良い絵ではありませんよね。
だから大丈夫、、、大丈夫か大丈夫でないか、難しいところかな。
…作曲
この前、作曲を始めてましたけど、今は止まっています。
買ったキーボード(鍵盤)全然触ってない。
クォータニオン(人体 3DCG モデル)に付きっ切りって感じです。
キーボードに触るとプログラミングのスピードが落ちると思って。
あと、作業(毎日15分でも鍵盤の練習をすれば上達する)ということで鍵盤に触るのはつまらないと思って。
落ち着いてから普通に触りたいです。
(訪問者のどんなニーズと この記事がつながるか)
- 日記を読みたい
2025年7月12日
プログラミング TC4.0J のバグは本当?
- Turbo C++ 4.0J を購入した。
- しかし、大きなバグのウワサ話を聞いた。
- そのバグの真相を探る。
- その結果。
1. Turbo C++ 4.0J を購入した。
Turbo C++ とは、30年前のとても古いパソコンで活躍していた「プログラミングを行うためのソフトウェア」(開発環境、IDE)です。
もともと Turbo C++ ver 1.01 を持っていましたが、将来使うだろうと考えて Turbo C++ ver 4.0J をヤフオクで購入しました。
30年以上も前の品物なのに「未使用新品」で、落札価格は 15,000円。
▼USB FDD ドライブで Win 11 に取り込み、エミュレータ上でインストール&起動。
どうして、今の今から 30年前のプログラミング環境をわざわざ購入するのかというと、面白いからですね。
昔のパソコンというのは仕組みがシンプルで、ユーザー側でいろいろテクニカルな遊びができるんです。
それに昔のプログラミング環境やソフトウェアは今よりも手厚いサポートがあって、ヘルプとか懇切丁寧に作られていて、快適な環境になっているんです。
今の若い人にとっては「うわっなんだこれ!こんな原始的な動きか!」とか「あれっこれって今の Windows と変わってないじゃないか!」、「ヘルプが丁寧だな、ヘルプと同じ内容の紙の説明書(椅子に腰かけてパラパラめくれる)まであって金かけてるんだな」というおどろきがあると思います。
2. しかし、大きなバグのウワサ話を聞いた。
Tourbo-Cには4.0という恐ろしいバージョンがあって、強烈なバグを抱えたまま出荷されました。
DOS上のプログラムがTurbo-C4.0で開発されたものならバグ回避のためのコードが含まれている可能性が高く、移植時の問題になるかもしれません。
強烈なバグ:
プログラムが64キロバイトを超える配列を使っている場合、64キロバイトの境界線を越える要素のアドレス計算が間違っている。
https://oshiete.goo.ne.jp/qa/455191.html(2025年9月17日(水)以降リンク切れする予定)
今だったら、速攻でアップデートが配信されるだけのことですが、当時はお店でディスクを買ってネット無しでインストールして…だったのでこういうバグはそう簡単には修正されません。
それでも「パッチ」(修正ソフトウェア)がパソコン通信や郵便で提供されることはありました。
だからインターネットで当時のそういうパッチが無いかと探しましたが見つけられませんでした。
3. そのバグの真相を探る。
「強烈なバグ」と言うほどなので、どんなもんかと思って再現させてみることにしました。
…で、いろいろやってみたんですが、当時の開発環境というのは「メモリモデル」を6個の中から選択するもので、その挙動がいろいろなので調べていて収拾がつかなくなり、何がバグで何が正当な仕様なのか分からなくなりました。
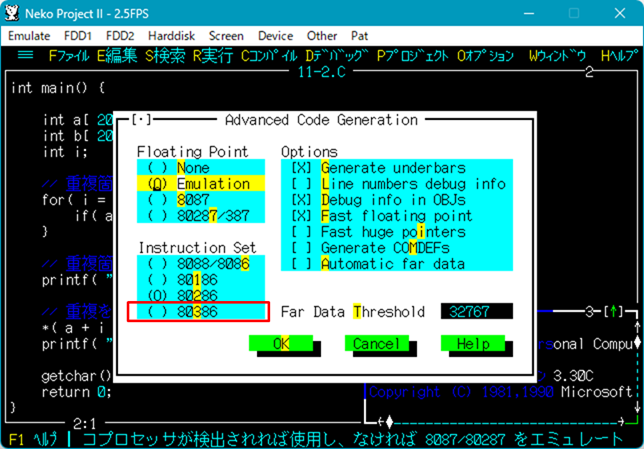
▼ヘルプにメモリモデルについての説明があります。
▼Oオプション>C:コンパイラ>C:コード生成 で…
▼画面左上にメモリモデルの選択があります。
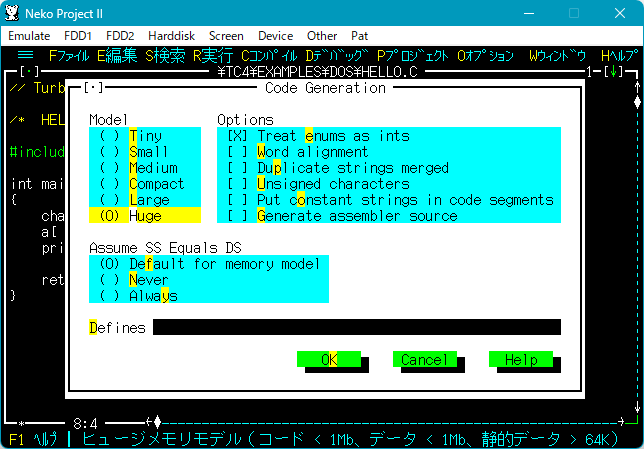
そこで、とりあえず自分で調査用のプログラムを組んで、「事実」を並べてみることにしました。
ヘルプを読んでもその内容が間違っている場合があるし、読んでる私が誤解して読む場合もあり得ます。
それなら、目の前で起こっている「事実」を並べたほうが確かな情報であり、問題を浮き彫りにするのに役立つと思いました。
まず前提として、
当時のメモリのしくみは、諸般の事情により、「セグメント:オフセット」という方式が採用されていた。
1つのセグメントは 64KB の容量を持ち、その 64KB 内のアドレスは:の右側の「オフセット」部分で表される。
オフセットは 0000 ~ FFFF で表され、これは 256 x 256 = 65,536、つまり容量 64KB を意味する。
そして調査した結果(事実)として(6点)、
事実1. いずれのメモリモデルでも、配列の「要素数」の上限は 65,535 個までだった。
たとえば、
char a[ 65535 ];
これが上限です。
65536 とか指定して、これを超えると、
Array size too large in function main.
というエラーが出ます。
事実2. いずれのメモリモデルでも、配列の「容量」の上限は 64KB(65,536KB)だった。
たとえば、
char 配列(要素1つが 1 byte)なら「要素数」65,535個までで、「容量」64KB。
int 配列(要素1つが 2 byte)なら「要素数」32,767個までで、「容量」64KB。
どういう形にせよ、容量 64KB を超えないようになっています。
超えると、
Array size too large in function main.
というエラーが出ます。
つまり、事実1、事実2 により、Turbo C++ 4.0J では、配列は、
- 要素数 65535 個まで、
- 容量 64KB まで、
という仕様で固定のようです。
事実3. いずれのメモリモデルでも、malloc() で確保できる容量の上限は 64KB(65,536KB)だった。
たとえば、いずれのメモリモデルでも malloc() を使って 128KB のような容量を確保することはできませんでした。
事実4. 上位のメモリモデル Compact, Large, Huge では、malloc() で「容量」64KB を「複数」確保できた。
上位のメモリモデル Compact, Large, Huge では、malloc() で確保できる容量の「個別の上限」は 64KB(65,536KB)であることには変わりはありませんが、malloc() で「容量」64KB を「複数」確保できました。
上位のメモリモデルでは、データセグメント下記※が 1MB あるので、その容量を超えさえしなければ、複数確保可能ということらしいです。
※ データセグメントとはプログラムの内、「データ」の部分を保存するメモリ領域のことで、コードセグメントにはプログラム自体を置きます。これは現在の Windows でも同じ方式となっています。
事実5. 上位のメモリモデル Compact, Large, Huge では、farmalloc() で64KB 以上の容量を確保できた。
malloc() では 64KB まででしたが、farmalloc() を使うと 128KB など自由な容量で確保できました。
malloc() は「エム・アロック」、人によっては「マロック」と読むと思います。
farmalloc() とは、far, malloc をつなげたものです。
far とは「遠い」という意味の英単語です。
64KB 内であれば「近い」のでその内部を指すポインタは near ポインタと呼びます。
64KB を超えて別の 64KB の中を指すポインタは「遠い」ということで far ポインタと呼びます。
64KB 以上の容量のメモリを扱うためには、far ポインタが必要、ということで farmalloc() というものが用意されていると考えられます。
読みは「ファー・エム・アロック」、「ファー・マロック」だと思います。
事実6. 配列と、「malloc() で確保されたデータ領域」では、オフセットが上限を超えると「ラップアラウンド」した。
セグメントは固定で、オフセットは上限の FFFF を超えると、セグメントはそのままに、オフセットが 0000 に戻ってしまっていた。
そのとき、配列の前方の要素と、後方の要素が同じアドレスを指していた。
後方要素に代入すると前方要素にも代入される状態です。
これは「ラップアラウンド」と呼ばれる現象です。
その結果。
ウワサの「強烈なバグ」、
>プログラムが64キロバイトを超える配列を使っている場合、64キロバイトの境界線を越える要素のアドレス計算が間違っている。
これは、「配列」と言っていて、「64KB」を問題にしており、「アドレス計算がおかしい」と言っています。
これはまさに、
”配列の要素のアドレスの「オフセット部分」が FFFF を超えると 0000 にもどってしまい、メモリ領域(セグメント)の先頭とメモリ割り当てがかぶってしまう”、
…「ラップアラウンド」のことを言っているように思えます。
解決として、「farmalloc() を使って 64KB 以上の領域を作成して、その領域をポインタを使って配列みたいにアクセスし、64KB の境界を超えたところでアドレス計算を間違えている」かどうか、試してみたところ…
| ▼64K の境界付近にカウンタ変数 i の値をそのまま置く。 | ▼i 番目にはちゃんと i の値が格納されているし、それを読めている。 |
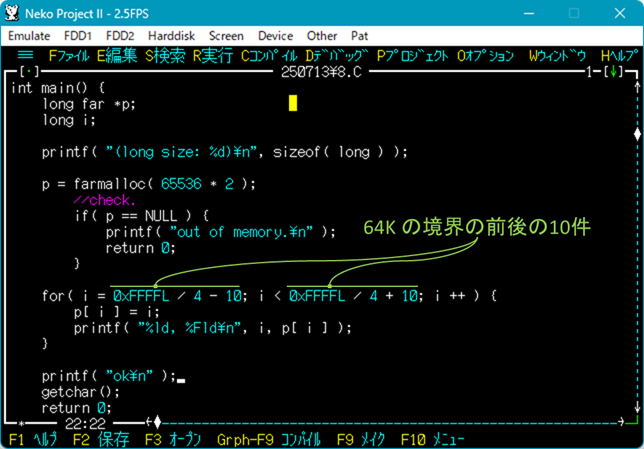 | 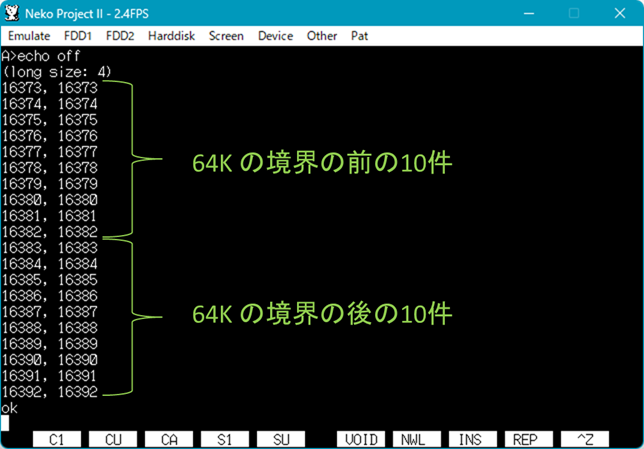 |
うーん、まったく問題ないですねぇ。。
やはりウワサは間違いだったのかなぁ。
※ 2025年7月16日追記 ↑これは間違えていました。(図のように far ポインタを使うと結局ラップアラウンドするので huge ポインタを使うのが正解です)次の記事(次の記事※A)を参照ください)
でも、もちろん私の調査は完ぺきではなくて、
- 調査はリアルモードだけで行っているが、プロテクトモード(現在の Windows のアプリはどれもプロテクトモード)ではどうなのか。プロテクトモードは基本的に広いメモリを扱える環境です。
- 調査は main() のローカル変数だけで行っているが、main() の外側のグローバル変数ではどうなのか。
…というところは今回調査していません。
※ 2025年7月18日追記 main() の外側のグローバル変数でも同じ症状でした。
でもまぁ、そこまで調べなくても、たぶん、ウワサは「ラップアラウンド」の動きを見てバグだと思い込んだ、と見ていいんじゃないか、という気がしています。
ということで、安心して Turbo C++ 4.0J を使える感じで、めでたしめでたし、ということです。
以上ですが、
その他、補足事項を書いておきます。
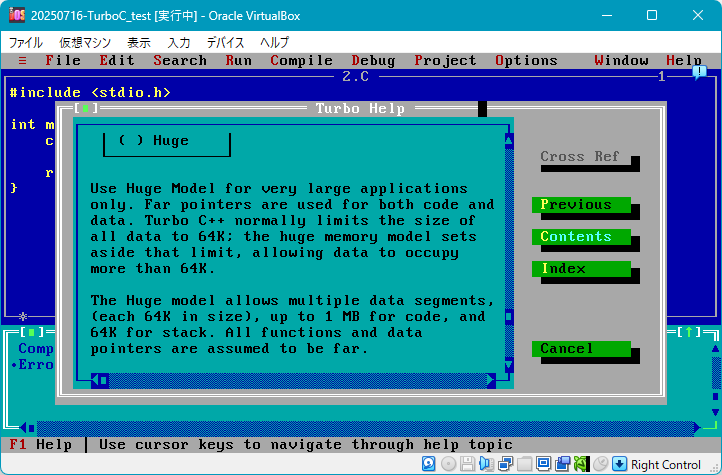
▼ヘルプの Huge についての説明
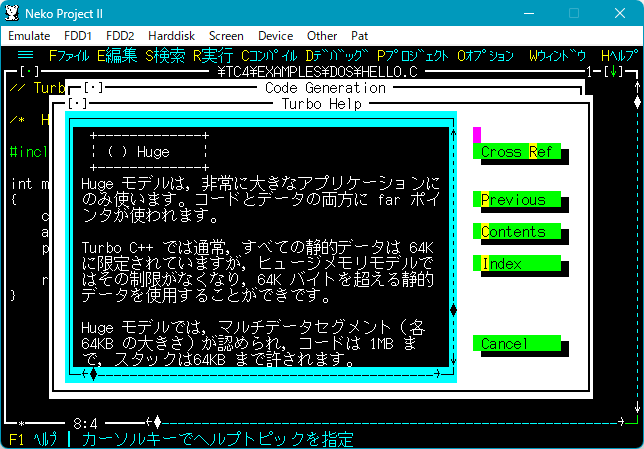
「静的データ」って何のことを言っているんだろう…。
「静的データ」の対義語は「動的データ」で、動的データとは malloc() で確保したメモリのことだと思います。
だから「静的データ」とは配列のことかなと思います。
>静的データは 64K に限定されています
確かに配列は 64KB までの容量までしか使えませんでした。(事実2)
>が、ヒュージメモリモデルではその制限がなくなり,64K バイトを超える静的データを使用することができます。
Huge モデルなら 64KB 以上の配列を使用できる??
下図の通り、できなかったんだけど… orz
| ▼メモリモデルに Huge を選んで、 | ▼データセグメント 64K を超えて配列を宣言すると、要素のアドレスが重複する |
|
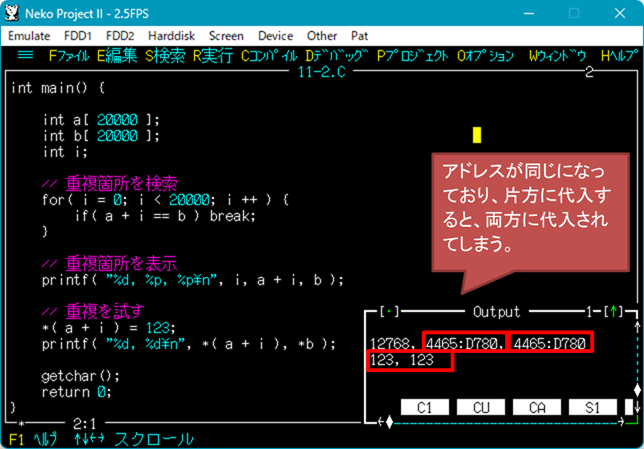 |
このヘルプのあいまいさ(間違い?)が、強烈なバグのウワサの発端になったんじゃないか、、という気もします。
(訪問者のどんなニーズと この記事がつながるか)
- Turbo C++ の話を聞きたい
- プログラミングの話を聞きたい
- 日記を読みたい
2025年7月16日
プログラミング TC4.0J のバグは本当? その2
- まだ腑に落ちない
- 他バージョンでも同じ現象がある!
- 英語圏の情報によれば
- 決着
1. まだ腑に落ちない
30年前の開発環境 Turbo C++ 4.0J のウワサの「強烈なバグ」、
>プログラムが64キロバイトを超える配列を使っている場合、64キロバイトの境界線を越える要素のアドレス計算が間違っている。
これについて前回調査し、
『たぶん、ウワサは「ラップアラウンド」(メモリアドレス指定のセグメント部分はそのままにオフセット部分だけが FFFF のあと 0000 へ戻る)の動きを見てバグだと思い込んだ』
と結論しましたが、まだ腑に落ちないのでさらに調べました。
2. 他バージョンでも同じ現象がある!
他の機種、他のバージョンの Turbo C++ でも同じ現象があるのか調べてみました。
「Oracle Virtual BOX」 + 「FreeDOS 1.3」 + 「英語版 Turbo C++1.01」という環境にて、
| ▼同様にメモリモデルで Huge を選択し、 | ▼データセグメント 64K を超えて配列を宣言すると、要素のアドレスが重複する |
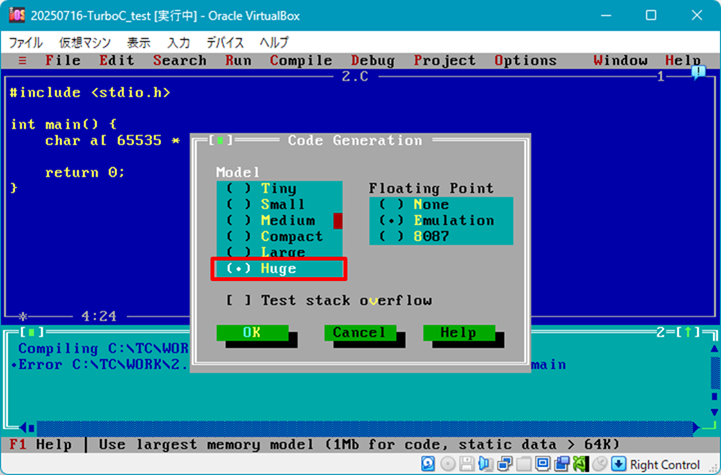 |
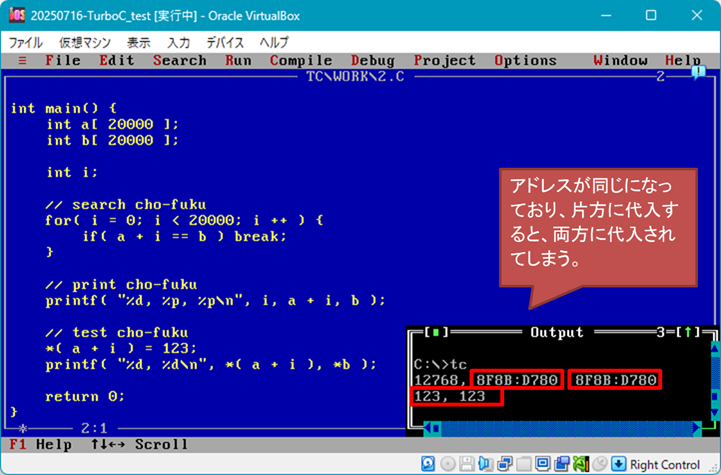 |
…同じ現象になっていますね。
| ▼「英語版 Turbo C++1.01」のヘルプ | ▼「日本語版 Turbo C++ 4.0J」のヘルプ |
 |
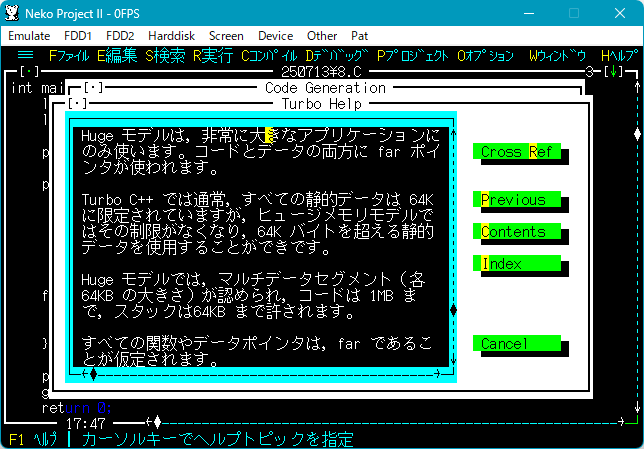 |
これを Google 翻訳すると、
Hugeモデルは、非常に大規模なアプリケーションにのみ使用してください。
farポインタはコードとデータの両方に使用されます。
Turbo C++は通常、すべてのデータのサイズを64Kに制限しますが、Hugeメモリモデルはこの制限を撤廃し、データが64Kを超えるサイズを占有できるようにします。
Hugeモデルでは、複数のデータセグメント(それぞれ64Kのサイズ)が許可され、コード用に最大1MB、スタック用に最大64Kまで使用できます。
すべての関数とデータポインタはfarポインタであると想定されます。
日本語版のヘルプとまったく同じことを言っていて、しかもどちらにしても実際の動きは説明と異なっています。
3. 英語圏の情報によれば
英語圏の人々の中でこのことについて情報提供していないか「turbo c array huge memory 64K」というキーワードでWEB検索したところ、普通に話題になっていました。
「Turbo C で大規模配列を使用する」(Google WEB翻訳、表示に数秒時間がかかります)
この記事では私が調べていた「ラップアラウンド」の現象とか、解決するには「配列の代わりに farmalloc() によるポインタを使う」とか、ほとんど同じことを説明しています。
でもハッキリと、「これはバグのようです」と言っています。

英語版ではウワサのバグは無いことを期待していましたが、共通して存在しているようです。
また、私の前の記事で「farmalloc() を使って確保した領域であれば問題がない」と書きましたが(前の記事※A)、そのとき領域自体は正しく確保されますが far ポインタを使ってアクセスすると結局「ラップアラウンド」していました。
それはこの部分を読んで気づくことができました。

これについては「huge ポインタはラップアラウンドを気にすることなくインクリメントできる」とヘルプにもあります。
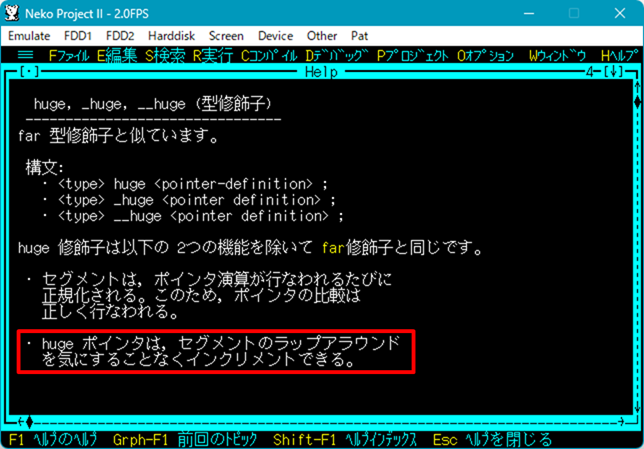
| ▼far ポインタを huge ポインタに変更した。 | ▼64K を超えるところでセグメントが正しく次に移っている。 |
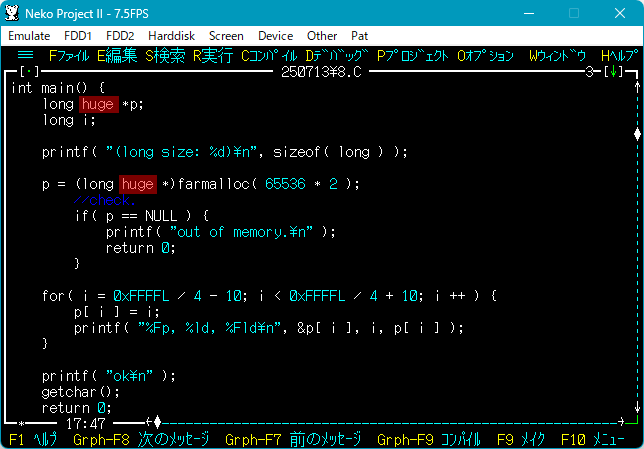 | 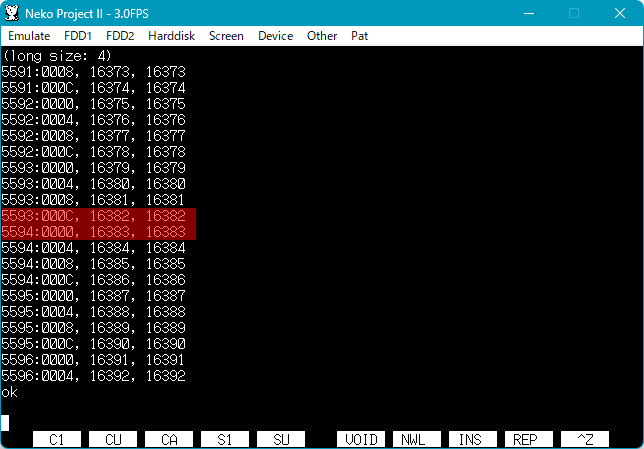 |
※「64K を超えるところでセグメントが正しく次に移っている」と書きましたが、アドレスのオフセット部分を見ると 0000~000F までの 16 バイトごとでセグメントが変更されています。セグメント切り替えのオーバーヘッドをおさえることを考えるとこういう仕様になるのだろうか…
4. 決着
ウワサの「強烈なバグ」、
>プログラムが64キロバイトを超える配列を使っている場合、64キロバイトの境界線を越える要素のアドレス計算が間違っている。
これの真相は、「確かにその通り」だけど、このバグは Turbo C++ 4.0J に限ったことではなく、Turbo C、Turbo C++ の少なくとも Turbo C++ 4.0J までの製品で共通して存在するバグだ、と言えそうです。
その解決は、容量が大きい配列は、配列を使わずに farmalloc() を使ってメモリを確保し、そのアクセスは far ポインタではなく huge ポインタを使う。
…ということで決着かな。
補足1:
「セグメント:オフセット」のメモリのしくみは当時のコンピューターとしては基本中の基本で、Turbo C、Turbo C++ という製品を数年間販売してその部分についてずっとバグがある状態だった、というのもまた腑に落ちませんけど…
たぶん、「farmalloc() で huge ポインタを使うことでラップアラウンドを回避できる」としている(ヘルプでそう説明している)ところを見ると、「配列を 64K を超えて宣言したときにラップアラウンドする」というバグくらい開発元の Borland は認知していたんじゃないかな。
ヘルプで「Huge メモリモデルでは静的データにおいて 64K の制限を撤廃した」と書いているなら、「Huge メモリモデルのときに配列の宣言があったら、これは内部的に farmalloc() と huge ポインタを使うように変換」していればバグ修正となったんじゃないか、、
でも静的データは配列とは限らないから、すべての変数宣言で farmalloc() + huge ポインタにしなければ実現できない?または変数宣言で 64K を超えたかどうかを毎回チェックして超えた場合だけ、、
どれも現実的ではないから実現できなかったのかな。
補足2:
前回の 2025 年 7 月 12 日の記事で最初に、
>もともと Turbo C++ ver 1.01 を持っていましたが、将来使うだろうと考えて Turbo C++ ver 4.0J をヤフオクで購入しました。
30年前のソフトウェアを将来使う??
私は『今から PC-9801 のアセンブリ言語やハードウェア(メモリ等)の制御、そして当時の C 言語を学べば、現在のコンピューター業界に通用する技術を身に着けることが出来る』と考えていて、それで「将来使う」と言っていますが、30年前の技術を学ぶのはかなり遠回りなのも確かです。
でも、今の時代で活躍している年配の技術者の方々の多くは、PC-9801 の時代に PC-9801 という(今から見れば)シンプルな機械をベースに多くの技術を学んできたと思います。
現在の Intel core シリーズの CPU は 8086 プロセッサ(= PC-9801)の延長線上にあることも考えると、同じくらいの技術力を得るためにはこれは正統な流れではないかと思います。
(訪問者のどんなニーズと この記事がつながるか)
- Turbo C++ の話を聞きたい
- プログラミングの話を聞きたい
- 日記を読みたい
2025年7月18日
プログラミング 「クォータニオン」はじめました3
- 人型のプログラムが完成に近づいてきました。
- このプログラムの概要。
- 製作はもうしばらくかかる。
1. 人型のプログラムが完成に近づいてきました。
人間の手や足などのパーツの親子関係に沿って、各パーツを正しく回転し、正しい位置に描く「座標計算」がひとつの山場でしたが、なんとか越えられました。
今まで同じものはできていたんですが、回転計算部分にクォータニオン(数学の四元数)を導入し、それで作るのは初めてでそれが今回できた、ということです。
できたところで試しに人型のサンプルを作り、キャンドル・スピンのポーズを取らせてみました。
| ▼バンダイ作(RG νガンダム) | ▼わたし作 |

|
クォータニオンを使っているからこれができるっ!
……というわけではないんですが、クォータニオンを使うと、こういうポージングがうまくいきやすいっていうのかな。
プログラムは普通に問題なく使用できるみたいで良かったです。
2. このプログラムの概要。
この JavaScript プログラムは、「原理式を使った 3DCG」、「クォータニオンによる回転計算」、「モデルの親子関係」を使用した「典型的なプログラム」となっています。
典型的な中でも、少し画期的なのは baseModel の概念です。
baseModel があるからこそ、

このように、つま先を baseModel にすることで、このつま先をその場に固定し、つま先を中心に全体を傾かせるということが可能になります。(マイケル・ジャクソンのおどり)
このしくみがあることで、「地面を蹴って」ジャンプして、鉄棒を「つかみ」、「鉄棒を中心に」グルングルンと回る、という一連の動きがたやすくできるようになります。
キャンドル・スピンの例ではつま先を baseModel にすることでつま先を中心に回転させることができています。
この人型モデルはおなかを唯一の根(ルート)としたツリー構造(親子関係)になっています。
「だから根であるおなかから子へ向かって座標計算をするのだろう…」
…と考えがちですが、そうではなく、baseModel の概念を実現させるためには baseModel から座標計算を始めます。
つまり、baseModel から上流へ向かって座標計算し、下流へも向かって座標計算していきます。
固定されたモデルはそこで位置や回転が確定しているわけで、そこを基準に描くわけですから当然と言えば当然です。
根から計算を始めてしまうと様々な場面で計算が行き詰ります。
そういう知識は事前には無かったので、プログラムの全体的な作り直しを 22 回も行ってやっとでできた感じです。
3. 製作はもうしばらくかかる。
でもこのほか、顔を描くとかやらなきゃならないから、もうしばらくかかりそうです。
いつからこのプログラムに取り組んでいるんだろう…?
これらを作り始めた最初のファイル(テイク1)の作成日付が 2025 年 4 月 20 日とかで、今日が 2025 年 7 月 19 日なので、まる 3 カ月経っています。
真夏から秋にかけて完成かな。。
このプログラムは私の個人事業の一端を担うもの、という位置づけになっています。
私のその個人事業の最近の一カ月当たりの稼ぎ(売上)は、たぶん 10 円とかそういう感じではないかなと推測します。
利益としては赤字です。電気代や青色申告会の会費がかかってますからね。
早く完成させてイケてる品物を作らないと、採算と言うものがね、取れないんですよ旦那。
(訪問者のどんなニーズと この記事がつながるか)
- 面白い動きを見たい
- プログラミングの話を聞きたい
- 日記を読みたい
プログラミング 「クォータニオン」はじめました4
顔を描いた
顔を描くのは以前にやっていたので、その内容を適用してこんな感じになりました。
なんだか楽しそうだなぁ…
クォータニオンを使っているからこれができるっ!
……というわけではないんですが、クォータニオンを使えばこういうのがやりやすいっていうのかなぁ。
テクスチャ(ビットマップ画像の3D空間内への貼り付け)は処理が重すぎてできないので、ベクタ画像で実現させています。
ビットマップ画像は画素の集まりで、ベクタ画像は線をどこからどこまで引くのかという情報の集まりです。
ビットマップ画像の場合は 100 x 100 の画素の集まりだとすると 10,000 個の点を打つ作業が必要になりますが、ベクタ画像だと「ここからあそこまで線を引け」という1回の作業で終わるので処理が軽いです。
JavaScript の CANVAS タグでは beginPath(), closePath(), moveTo(), lineTo(), bezierCurveTo() など、線を描いたり塗りつぶしたりするベクタ描画機能があります。
それらは本来 2D 描画用の機能ですが、引数の値を 3D 計算してから渡すと、3D 空間内で適切に曲線を描くことができます。
特に bezierCurveTo() では、頂点の座標の他、ハンドルの座標も 3D 空間内でどこに位置するのかを計算して 2D へ投影し、その値を引数に渡してやると、あたかも 3D 空間内で曲線が存在しているかのような効果が得られます。
上のアニメの顔の目の曲線や、口の曲線も、bezierCurveTo() を使って描いています。
この後は、髪の毛モデルを取り付けます。
髪の毛モデルは親子関係ではなく、1つのモデルに別のモデルを追加するという形で作ります。
それも以前にやっていたので適用すれば良いという感じです。
HTML/CSS という名の強敵
正直言うと、、これらよりも、この IFRAME タグをウィンドウが大きくても小さくてもリキッドレイアウト的に伸縮するしくみのほうがよっぽど疲れました。
3DCG のプログラミングよりも、HTML/CSS のほうが私にダメージを与えてくる。
自分のプログラミングは内部は自分の手元にあるから分かるんだけど、HTML/CSS は目に見えない内部(ブラウザ内部)で何かやってるからそれが正体不明で苦しむ元になります。
で、伸縮する仕組みは一応できたみたいなんだけど、なんで出来たのかが分からない、いつの間にかできた、というありさま。理由が分からないから次回同じことをやるときに同じ苦しみを味わうことになる…
IFRAME の伸縮くらいシンプルなはずですが、読み込みのタイミングで内部のドキュメントのサイズや位置がいつ確定するのか、onload 内でレイアウトをいじっている場合、onload が終わるのはいつなのか、というその辺が苦しかったです。
(訪問者のどんなニーズと この記事がつながるか)
- 面白い動きを見たい
- プログラミングの話を聞きたい
- 日記を読みたい
2025年7月27日
プログラミング 「クォータニオン」はじめました5
髪の毛のモデルを取り付けしました。
画面の上下左右をクリックすると、そちら側を「押すように」回転します。
縦方向に回転すると分かりますが、「女の子お座り」しています。
髪の毛のモデルはどうやって作ったのか
髪の毛のモデルは Shade3D を使いました。
Shade3D でモデルを作ったら、Shade3D のファイル メニューからエクスポート>FBX... を選び、テキスト形式を選んで OK ボタンを押すと、テキスト形式の FBX ファイルが作成されます。
(Blender でも FBX 出力は可能ですが、バイナリ形式で出力されるので、別途ソフトウェアを使いテキスト形式に変換する必要があります)
そのテキストをテキストエディタで開くと、FBX フォーマットでデータが並んでいます。
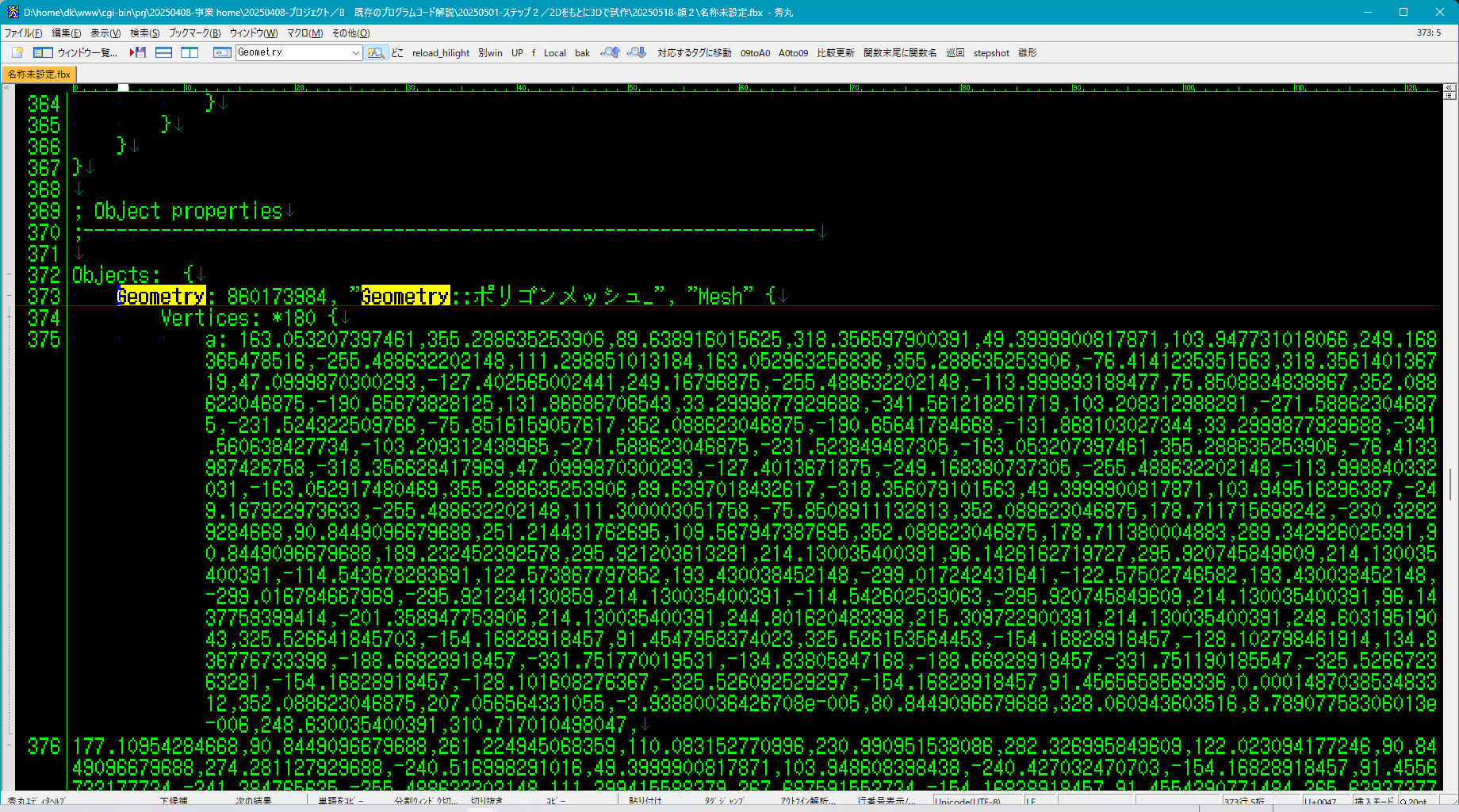
このデータが作成した髪の毛のモデルで、必要な部分のデータだけを取り出します。
取り出すには自分で作成したツールを使います。
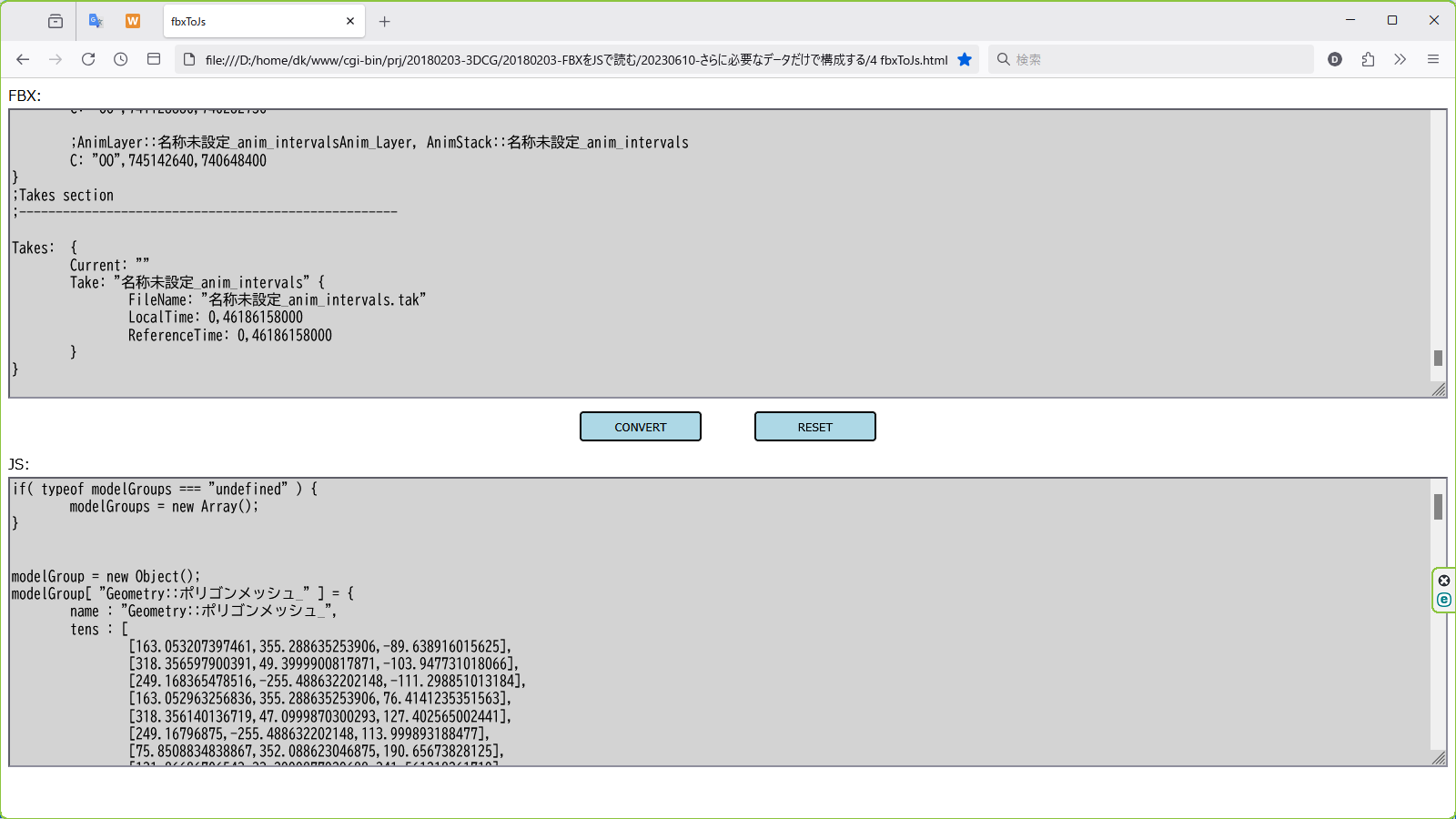
上半分にテキストの FBX をコピペして、中央の CONVERT ボタンを押すと、下半分に JavaScript を作成してくれます。
これを .js のファイル名で保存し、今回の人型 3DCG のモデルで使う、という寸法です。
このツールへのリンクは下記にあります。
Blender を使う場合
Shade3D は有料で、昔、買い切りのソフトウェアでしたが、途中からサブスクリプションになり、一般の人には手の届かない品物になってしまいました。
なので、Blender を使いたい人も多いと思います。
(説明のために、上記で使っていたテキスト形式の FBX ファイルをバイナリ形式に変換し、Blender で「ファイル>インポート」しました)
▼Blender でモデルを作ったら、ファイルメニュー>エクスポート>FBX (.fbx) を選びます。
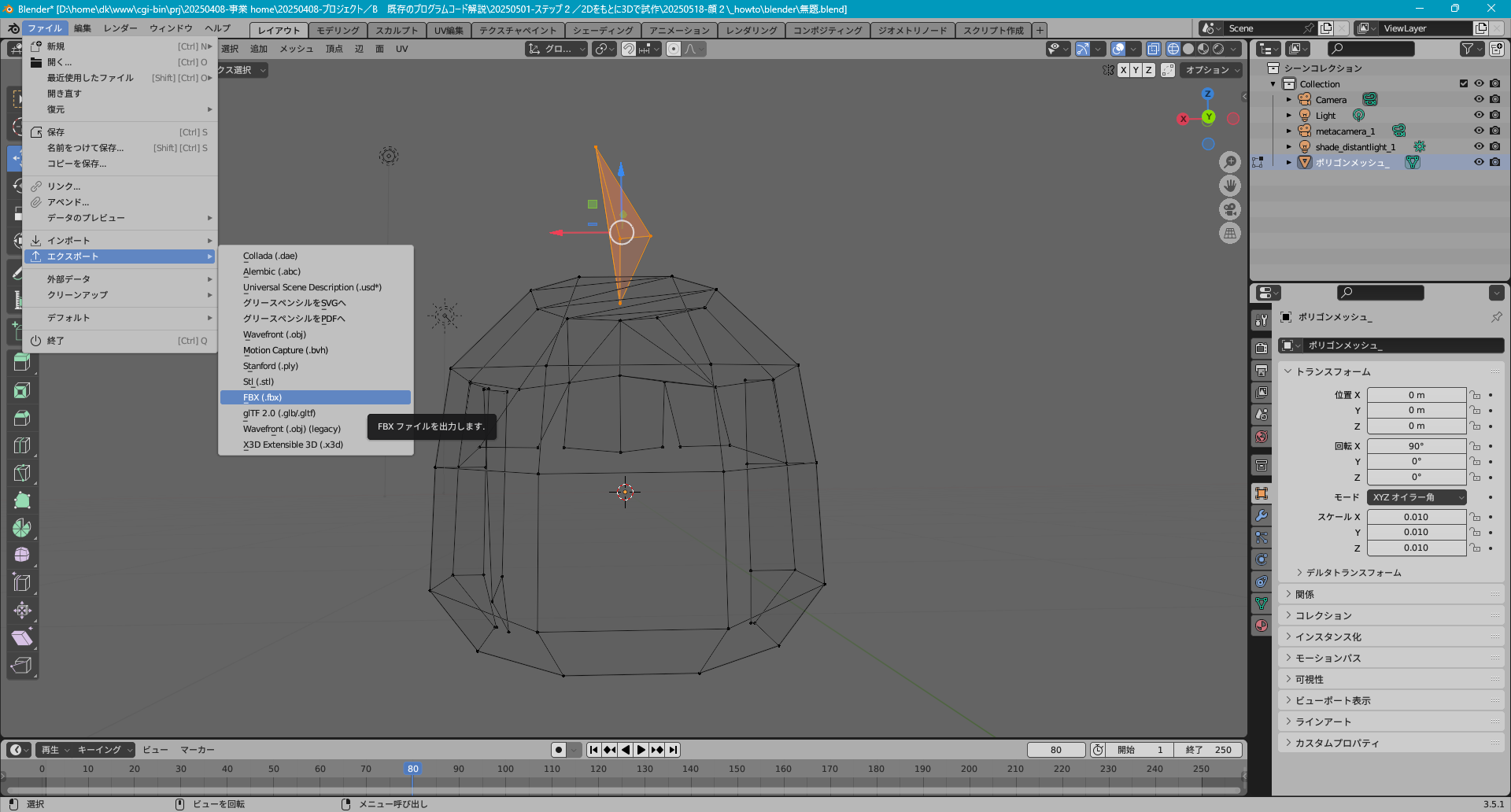
(上記で使っていたテキスト形式の FBX を下記のツールでバイナリ形式に変換し、Blender で読み取り、そして「アホ毛」を取り付けました)
Blender の FBX 出力は私が使っているバージョン 3.5 ではテキスト形式が選べず、バイナリ形式のみとなります。
どのバージョンでもテキスト形式に対応していないなら下記のツール「FBX Converter」を使いましょう。
▼そこで、MAYA とか AUTOCAD で有名な AUTODESK の「FBX Converter」を使います。
そのサイトへのリンクはここ
▼起動するとこんな画面が表示されます。
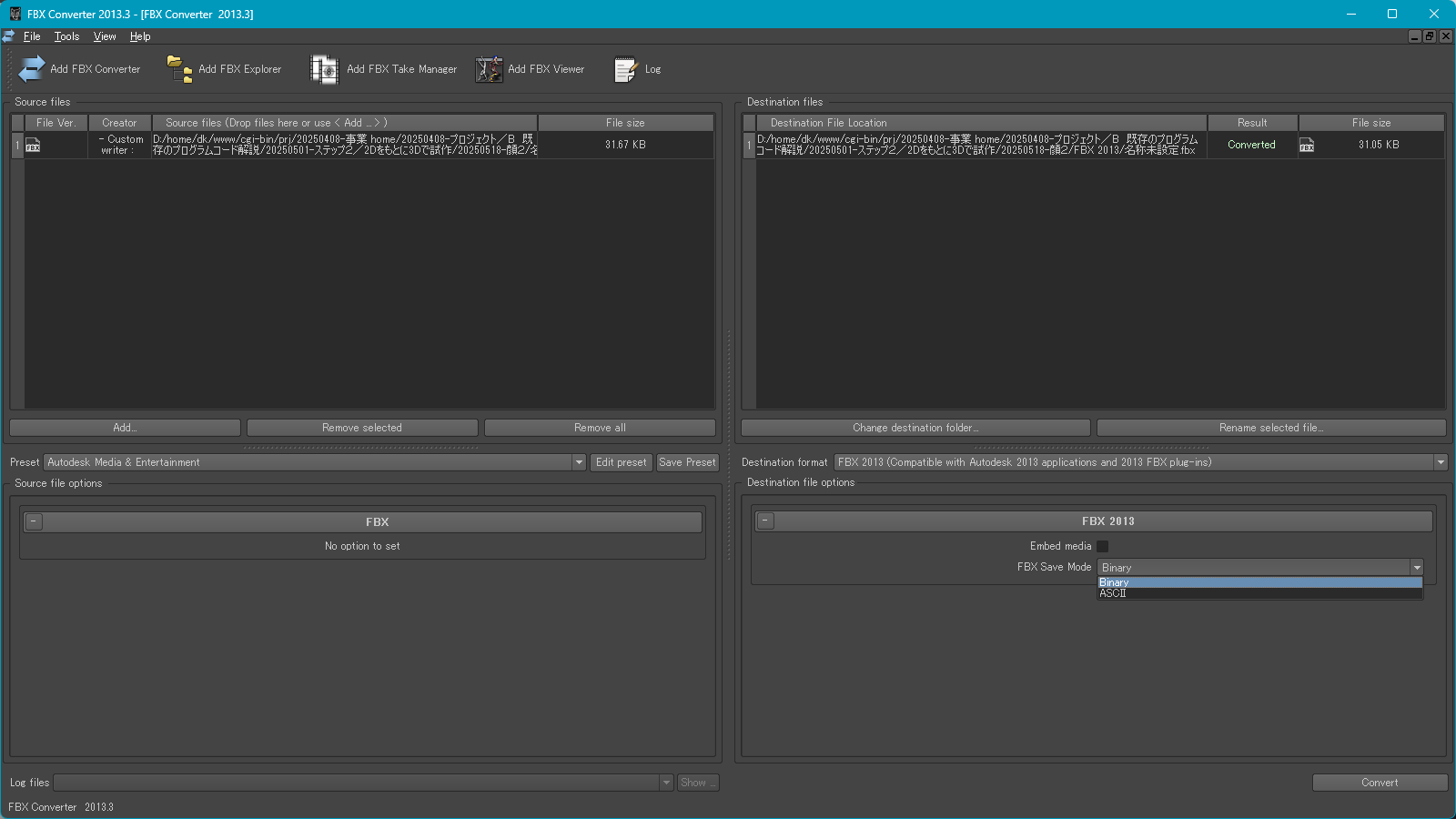
左の画面に、「Blender で出力したバイナリ形式の FBX ファイル」をドラッグ&ドロップし、右の画面の右下で Binary と ASCII を選べるのでテキスト形式を意味する「ASCII」を選んで、一番右下の Convert ボタンを押します。
するとテキスト形式の FBX ファイルが出来上がるので、テキストエディタで開いてすべてを選択、コピーします。
それを私が作ったツールの上半分に貼り付けして CONVERT ボタンを押し、下半分の内容をコピーして、
.js ファイルを作ってそこに貼り付けして保存します。
そして、
アホ毛が付きましたね。
途中でエラーとか出て対処しなきゃいけないかなと思っていましたが、エラーなしでストレートにできました。
私が作った「FBX→JS コンバーター」はこれです。
リンクを右クリックして「名前を付けて保存」して、ブラウザで開けば使えると思います。
JavaScript の中での使い方は、これ(ビューワー)を見てください。これも同じように保存して使ってください。
このビューワーが外部ファイルとして読み込む、ドラゴンの.js と、servicePack1.js、それぞれ保存してください。
(リンク先に飛ぶと漢字は文字化けすると思いますが、保存してテキストエディタで開けば正常に表示されると思います)
(これらのファイルは無くても、ビューワーだけでも立方体の線画を表示できます)
servicePack1.js があると色が付き、無ければ線画となります。
(我ながら、なんで servicePack1 なんて名前を付けたんだろ?)
ビューワーの html の最初の、
<script src="modelGroup_dragon.js"></script>
という部分を、「FBX→JS コンバーター」で作った .js ファイルに差し替えると自分のモデルに変更できます。
▼ビューワーの表示モデルをアホ毛のモデルに差し替え変更したところ

でっかく表示されるときは、画面に書かれているように、↑で遠ざかり、↓で近づきます。
奥の面が表示されていませんが、面には裏表の向きがあり、こちらを向いていない面は描画されません。
3DCG の表示のプログラムによっては描く場合が多いですが、このプログラムでは処理速度をおさえるために描画を行っていません。
どうやったら 3DCG データを JavaScript で表示できるのか、という 3DCG プログラミングについては上記ファイルの内容を見たり、このサイトの最初の「特別な記事へのリンク>3DCGプログラミングの方法」を見てください。
モデリングの難度
中学校、高校などの美術の時間に粘土や彫刻材料を使って何かの形を作ったことはあるでしょうか。
鑑賞に堪える綺麗なものを作るのは非常に難しかったと思います。
モデリングも同じで、ポリゴン(多角形のピース)を操るのは簡単ではありません。
私も初めてモデリングに取り組んだときは、「ガンダムのできそこない」みたいなモデルを作っていました。
「いったい、どうやったらあの顔の凹凸を表現できるのか」
と見当がまったく付きませんでした。

そこで、読んだのがこの本で、内容は MAYA での使い方、モデリングのやり方の話でしたが、Shade3D で MAYA と同様の機能を探しながら読み進めて、モデリングのノウハウをある程度学ぶことができました。
今では「ガンダムのできそこない」にはならず、ある程度思った通りのモデルを作ることができるようになっています。
この本では、著者が結構、性格に偏りがあると言いますか、ヘタクソな作品に対して普通に「ヘタクソ」と言っているので、それが我慢できない人には読めない本だと思います。
お客さんが手に取る作品というのはヘタクソであってはなりませんよね。
ちゃんとした良い物であるからこそ値段を付けて売ることができ、買う側も買うことができます。
ヘタクソなのに「上手だよ、いいよ、いいね」とか意味不明なことを言って、クリエイターを世に送り出すことのほうがずっと恐ろしいことだと思います。
買ったものがグシャッと崩れたものだったら、消費者として残念に思ったり、返品・返金を考えたりしますよね。
…でもまぁ、学ぶ最中であれば、全体的にヘタであっても、良いところを見つけて褒めることは必要なことだと思います。
この本の著者はトラの子供を崖から突き落として、這い上がってきた子供だけを育てるみたいなそういう人だと思います。
(訪問者のどんなニーズと この記事がつながるか)
- 面白い動きを見たい
- プログラミングの話を聞きたい
- 日記を読みたい